近日,我院林琛教授课题组在IEEE International Conference on Data Engineering会议(ICDE)发表论文”Adaptive Code Learning for Spark Configuration Tuning”,提出一种代码自适应的Spark系统自动调参方法。
Apache Spark是当前被广泛应用的大数据处理平台。为了达到最好的运行性能,程序提交时需要对260个系统参数进行配置。传统的人工配置方法不但费时费力价格昂贵,而且未必能达到最好的性能。与类似领域如数据库调参不同,Spark能支持语义和结构更复杂的程序导致调参不准确,运行数据更大导致调参时间开销更长,使用场景更多样导致调参性能不鲁棒,对自动调参方法的调参效果和效率提出了挑战。
针对以上问题,论文提出了一种离线训练-在线参数推荐的框架,该方法有三个创新。(1)对不同程序代码建模,能够对语义复杂的程序预测给定配置参数的可能运行时间。(2)训练样本程序在小数据集上运行,并通过自适应候选生成迁移到大数据集上预测性能较好的配置参数取值区间,在很小的时间开销内能处理更大数据集的调参问题。(3)自适应模型更新,适应多样动态的运行场景。
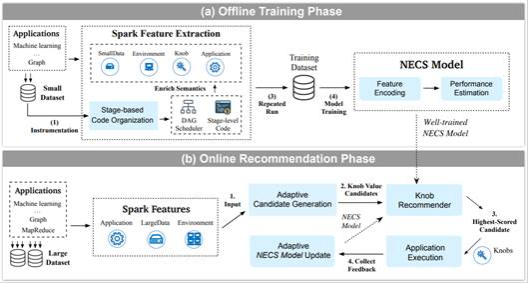
实验结果表明,该方法能在较短的调参时间开销下得到优于SOTA方法的调参结果。论文认为该方法对AutoML等领域也有借鉴意义。
ICDE是中国计算机学会A类会议。上述工作由林琛教授及其课题组成员,与清华大学李国良教授团队合作完成。林琛教授为第一作者,李国良教授为通讯作者。