近日,我院于计算机视觉领域顶级会议CVPR 2022(IEEE Conference on Computer Vision and Pattern Recognition),人工智能领域顶级会议IJCAI 2022(International Joint Conference on Artificial Intelligence)和AAAI 2022( the Association for the Advance of Artificial Intelligence)上发表多项重要研究成果:
1.Training-free Transfomer Architecture Search (发表于CVPR 2022,Oral)
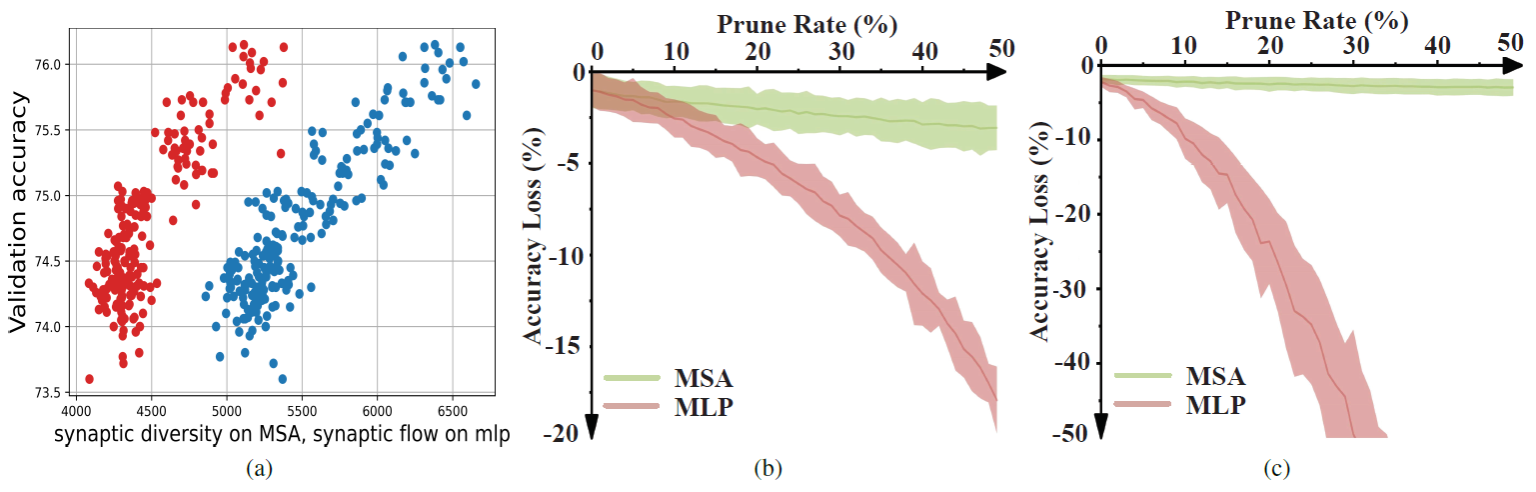
本文的第一作者是我院人工智能系2020级博士周勤勤,通讯作者是我院人工智能系纪荣嵘教授。本文提出一种基于无训练方式的Transformer结构搜索算法(Training-free Transformer Architecture Search,简称TF-TAS)。TF-TAS以模块化的方式从两个维度分别衡量Transformer中不同模块的不同性质,即多头注意力模块 (Multi-head Self-Attention,MSA)中的突触多样性和多层感知机模块 (Multi-Layer Perceptron,MLP)中的突触显著性,并以此作为评估模型的代理指标,称为DSS-indicator。通过随机搜索结合DSS-indicator的方式对不同的Transformer结构进行评估并搜索最优结构,在保证搜索结果的同时有效地提高了搜Transformer结构的效率。
2.Neural Architecture Search with Representation Mutual Information (发表于CVPR 2022)
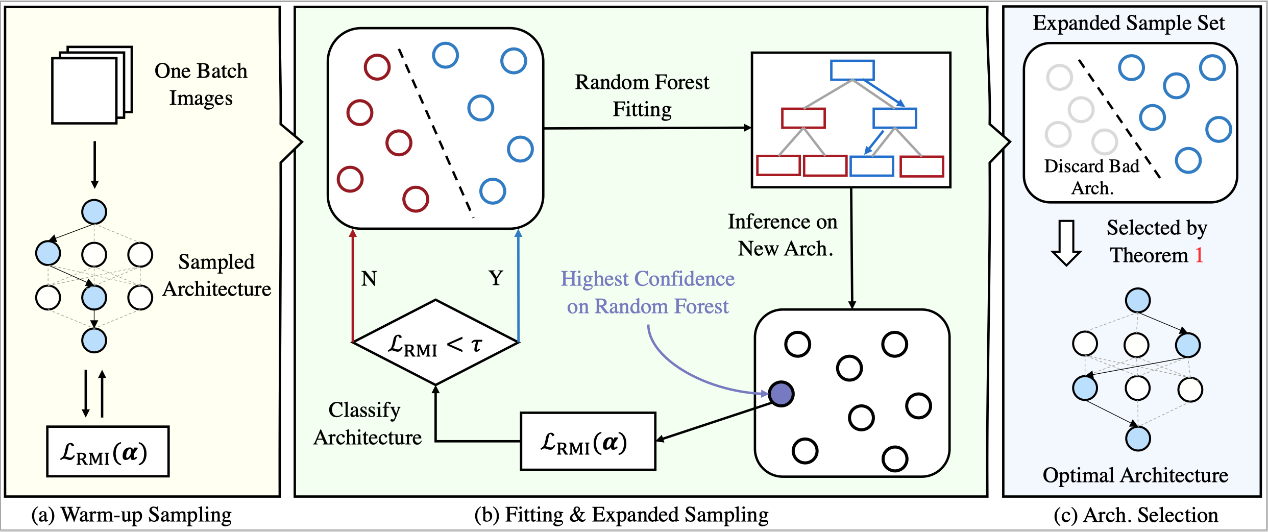
本文的第一作者是我院计算机科学与技术系2018级郑侠武博士,2021级硕士生费翔、张雷为共同一作,通讯作者是我院人工智能系纪荣嵘教授。本文提出一种基于特征互信息(Representation Mutual Information,简称RMI)的神经网络结构搜索算法。RMI-NAS首次提出使用神经网络特征表达互信息来进行精度评估,在此之上进一步提出了一种随机森林算法。该工作在理论上证明了使用随机森林算法的优化集合来获取最优网络结构即为优化全局最优。在实验上,RMI-NAS搜索速度更快,可以适配不同的搜索空间,可以得到一个更好、更为紧凑的模型。
3.DIFNet: Boosting Visual Information Flow for Image Captioning (发表于CVPR 2022)
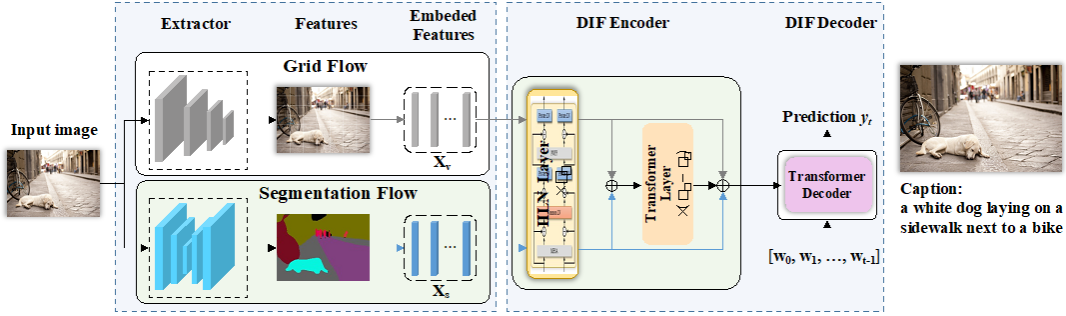
本文的第一作者是我院人工智能系2020级硕士生吴明瑞,通讯作者是我院人工智能系孙晓帅副教授。本文提出一种双信息流模型(Dual Information Flow Network,简称DIFNet)来解决在视觉描述任务中视觉内容对模型生成的描述贡献弱于部分生成的描述贡献的问题。DIFNet首次在视觉描述任务中引入分割特征来补充原网格视觉特征,并提出一种高效的特征融合模块(Iterative Independent Layer Normalization,简称IILN)用于凝练两种特征中最相关的信息并保留模态具体的信息,同时采用额外的残差连接来充分保留可能被过滤的视觉信息,DIFNet有效增强了视觉信息对模型生成描述的贡献程度。
4.IntraQ: Learning Synthetic Images with Intra-Class Heterogeneity for Zero-Shot Network Quantization (发表于CVPR 2022)
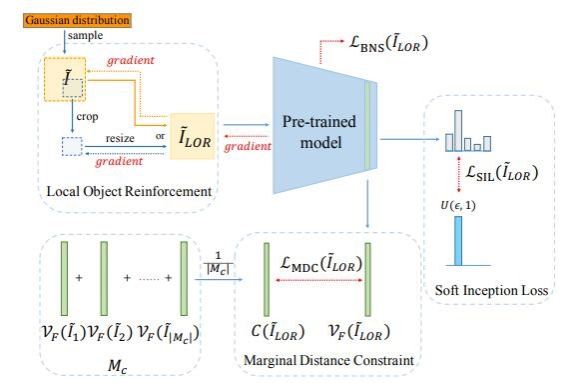
本文的第一作者是人工智能研究院智能科学与技术系的2021级博士生钟云山,通讯作者是我院人工智能系纪荣嵘教授。本文为无数据量化提出一种增强类内杂质性的方法(IntraQ)。IntraQ探索性地揭示了现有的无数据量化方法生成的数据存在着类内同质化的现象,其提出一种加强类内杂质性的方法,使得生成的数据能够拥有和真实数据类似的杂质程度,加强了生成数据的多样性,从而提高了量化模型的性能。
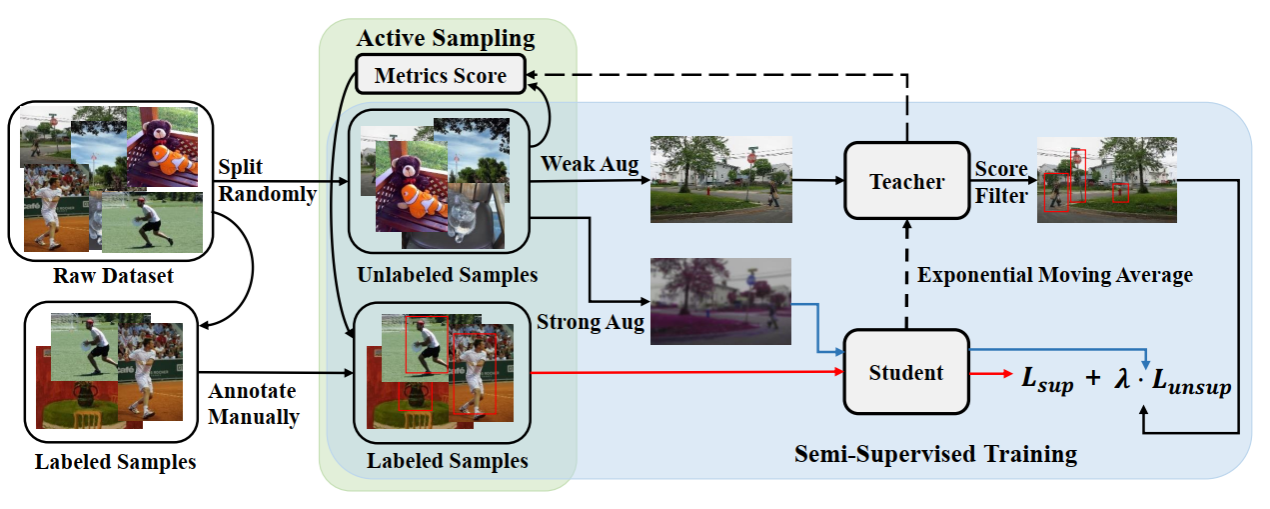
5.Active Teacher for Semi-Supervised Object Detection (发表于CVPR 2022)
本文第一作者是我院人工智能系2020级硕士生米芃,2020级硕士生林将航与博士后研究员周奕毅为共同一作,通讯作者是我院计算机科学与技术系曹刘娟副教授。本文针对半监督目标检测提出一种基于量化数据学习价值的主动学习算法(Active Teacher),Active Teacher针对工业标注数据成本大的问题,挖掘目标检测中学习价值大的数据。本文从不确定性、信息量和多样性等三个指标量化训练样本,通过少量的标注样本即可达到模型全监督水平。
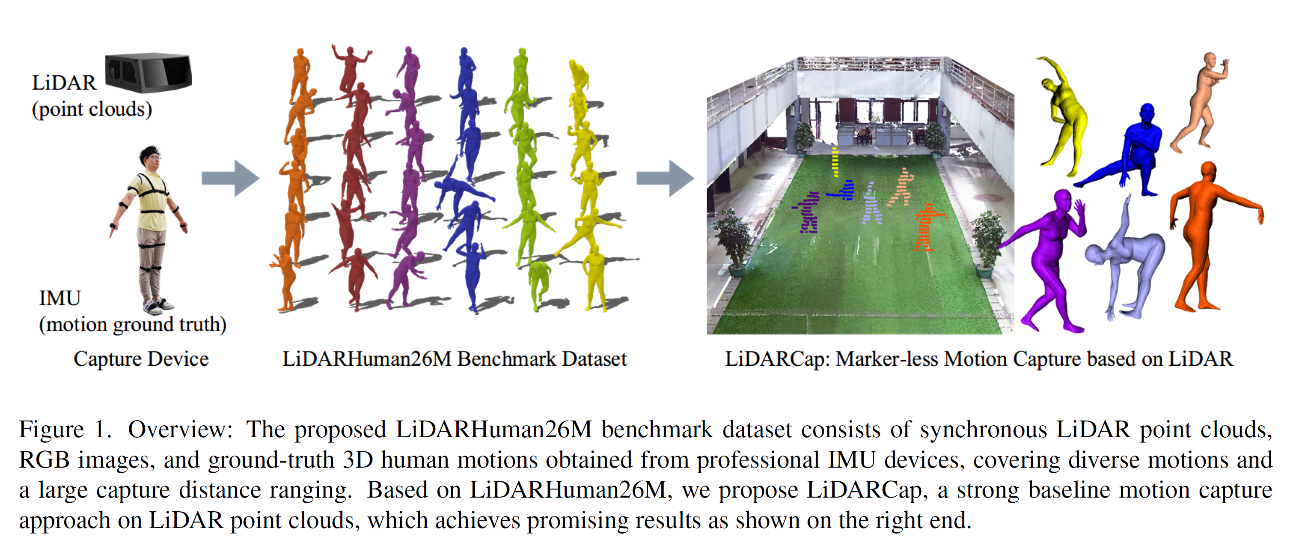
6.LiDARCap: Long-range Marker-less 3D Human Motion Capture with LiDAR Point Clouds(发表于CVPR 2022)
本文的共同第一作者是我院计算机科学与技术系2019级硕士生李嘉廉和2020年博士生章璟怡,通讯作者是我院计算机科学与技术系王程教授。本文提出了首个基于激光雷达进行人体运动捕获数据集LiDARHuman26M,它由时间同步过的激光雷达点云、RGB图像和由IMU动作捕捉系统采集的真实三维人体动作三个模态组成。本文进一步提出了用于激光雷达点云人体运动捕捉的方法LiDARCap。实验结果表明,相比于基于图像的方法,基于激光雷达点云的方法在远距离的场景下可以更好地捕捉人体的动作。此外,在KITTI数据集和Waymo开放数据集上的实验表明LiDARCap可以被推广到不同的激光雷达传感器的设置中。
7.HSC4D: Human-centered 4D Scene Capture in Large-scale Indoor-outdoor Space Using Wearable IMUs and LiDAR(发表于CVPR 2022)
本文的第一作者是我院计算机科学与技术系2019级博士生戴雨笛,通讯作者是我院人工智能系温程璐副教授。本文提出了一种以人为中心的4D场景捕捉方法(简称HSC4D),基于人与环境的交互进行多任务联合优化,实现大型室内外场景重建、多样化的人体动作捕捉及丰富的人与环境交互。此外,该论文还提出了一个包含三个大场景(1k-5k)的数据集,其中包括多样化的场景(攀岩馆、多楼层建筑、室外场景)和准确的全局动态人体运动。实验表明,HSC4D可以在无预先扫描的三维地图的情况下,仅使用安装在人身上的轻量化IMU和LiDAR,实现对三维动态环境和人体动作的准确高效建模。

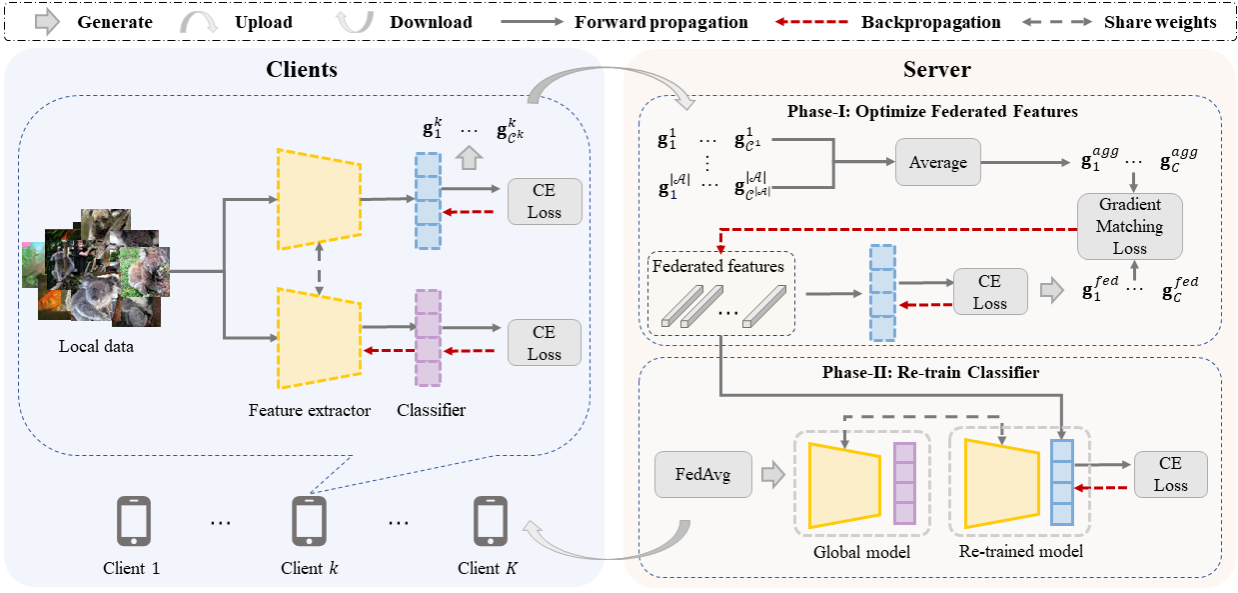
8.Federated Learning on Heterogeneous and Long-Tailed Data via Classifier Re-Training with Federated Features(发表于IJCAI 2022)
本文的第一作者是我院计算机科学与技术系2020级硕士生尚心怡,通讯作者是我院计算机科学与技术系卢杨助理教授。联邦学习旨在保护各参与方数据隐私的前提下,协作进行模型训练。但在真实应用场景中,客户端间的数据异构问题以及全局的数据长尾分布问题将导致模型表现不佳。论文首先发现了有偏分类器是导致全局模型在上述问题中性能不佳的主要因素。基于此,该文提出了一种在服务器端生成和优化联邦特征来重训练全局模型分类器的方法。该方法通过让联邦特征与客户端的真实数据在相同分类器上的梯度相似来优化联邦特征,从而在联邦特征和真实数据特征上进行优化能够得到相似的分类器。实验结果表明,该方法在3个数据集上都取得了优越的性能。
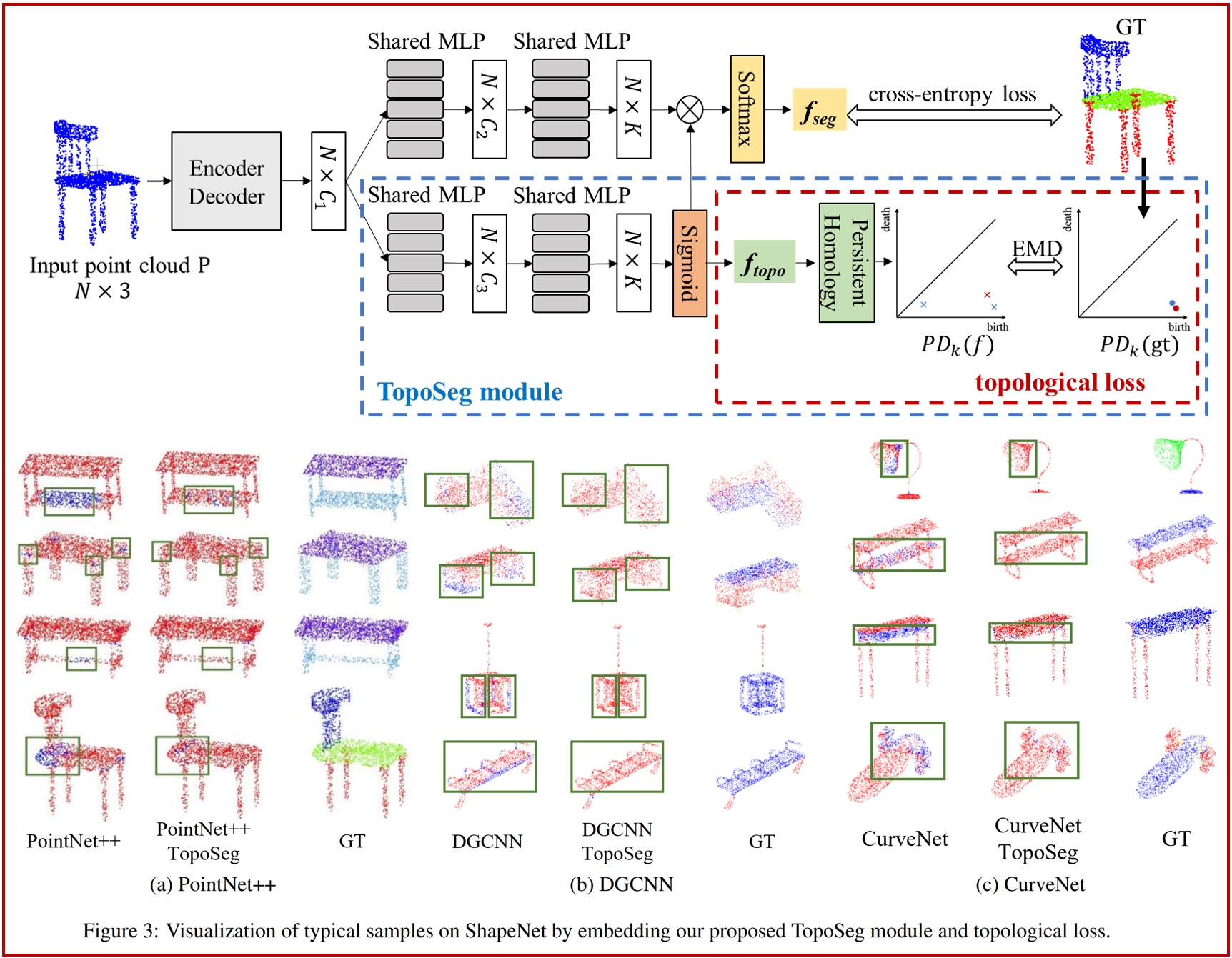
9.TopoSeg: Topology-aware Segmentation for Point Clouds(发表于IJCAI 2022)
本文的共同第一作者是我院刘伟权博士后/特任副研究员和2020级硕士研究生郭晗韵,通讯作者是我院臧彧副教授,其他合作作者包括我院硕士研究生张韦妮和王程教授,及加拿大滑铁卢大学Jonathan Li教授。本文将拓扑数据分析中的持续同调理论引入3D点云深度学习框架中,提出了拓扑感知的点云分割模块TopoSeg,用于约束点云分割结果的全局拓扑结构。该方法构建了一个拓扑损失函数对点云分割结果进行拓扑约束,并将TopoSeg模块和拓扑损失函数嵌入到点云分割网络中。实验表明,TopoSeg模块能够嵌入到点云分割网络中,保持点云分割结果的拓扑结构,提升点云分割性能与点云边缘点检测的鲁棒性。
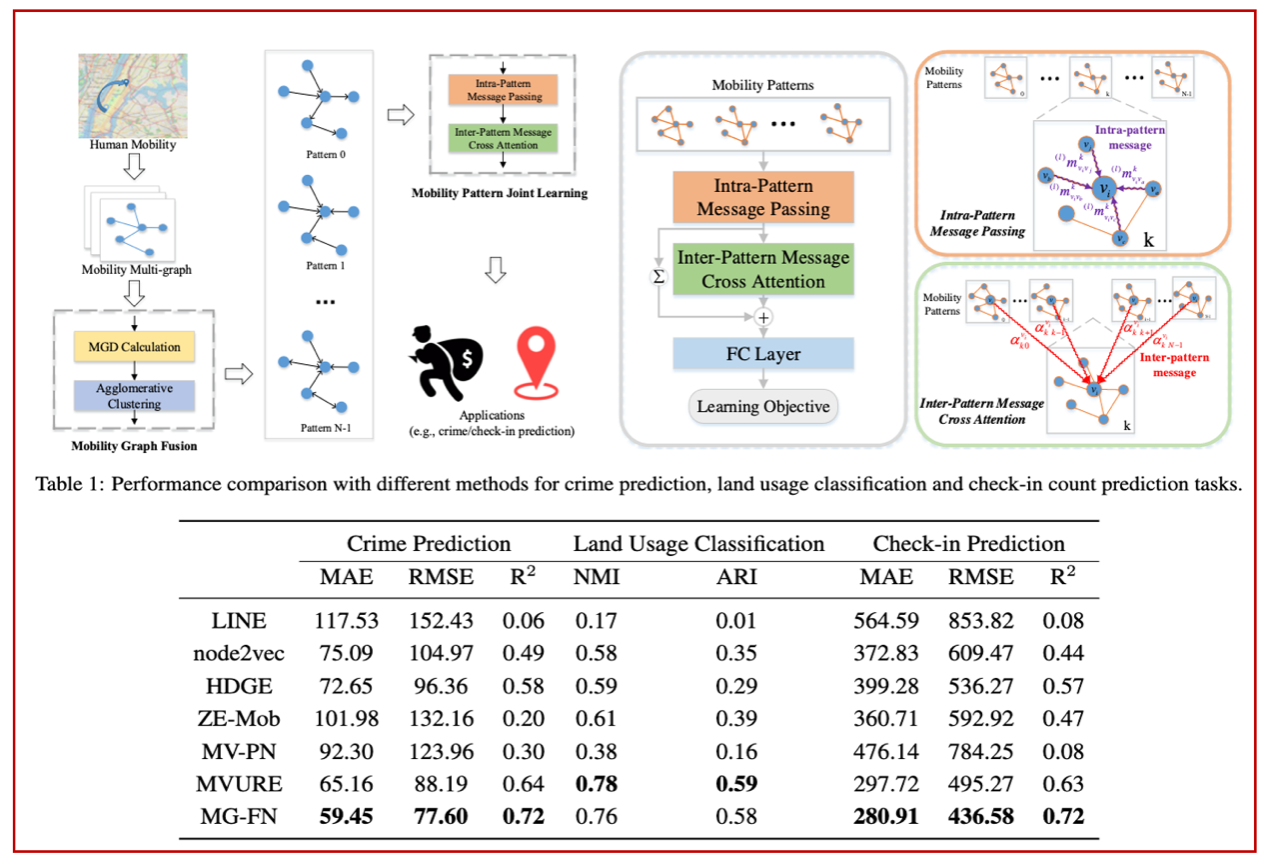
10.Multi-Graph Fusion Networks for Urban Region Embedding(发表于IJCAI 2022)
本文的共同第一作者是我院计算机科学与技术系2019级硕士生吴尚斌和闫旭,通讯作者是计算机科学与技术系范晓亮高级工程师,其他合作作者包括计算机系郑传潘博士生、程明教授、王程教授,以及澳大利亚Monash大学Shirui Pan和中科院信工所朱时超。本文针对城市区域表示学习方法泛化能力弱的问题,设计多图融合的城市区域表示学习机制(MGFN),以揭示城市复杂时空数据背后的通用嵌入表示,并对其下游任务的未来状态给出近似估计。在犯罪数量、土地利用类型和社交网络签到等三个跨域预测任务上开展实验验证,结果表明MGFN预测精度比基线方法最多提升了12.35%,且具有一定的泛化能力和可解释性。
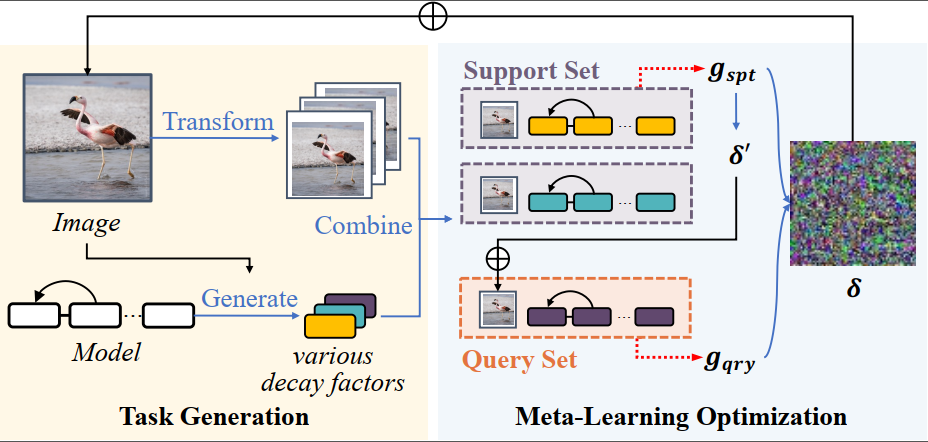
11.Learning to Learn Transferable Attack (发表于AAAI 2022)
本文的第一作者是我院人工智能系2020级硕士生方姝曼,通讯作者是我院人工智能系林贤明助理教授。本文提出一种基于任务扩增的迁移攻击方法,方法名为Learning to Learn Transferable Attack(LLTA)。LLTA从数据扩增和模型扩增两个角度构造任务,结合元学习的核心思想,让对抗样本适应所构造的任务,以此提升对抗样本的泛化性。该方法有效地解决了对抗样本迁移成功率低效的问题。
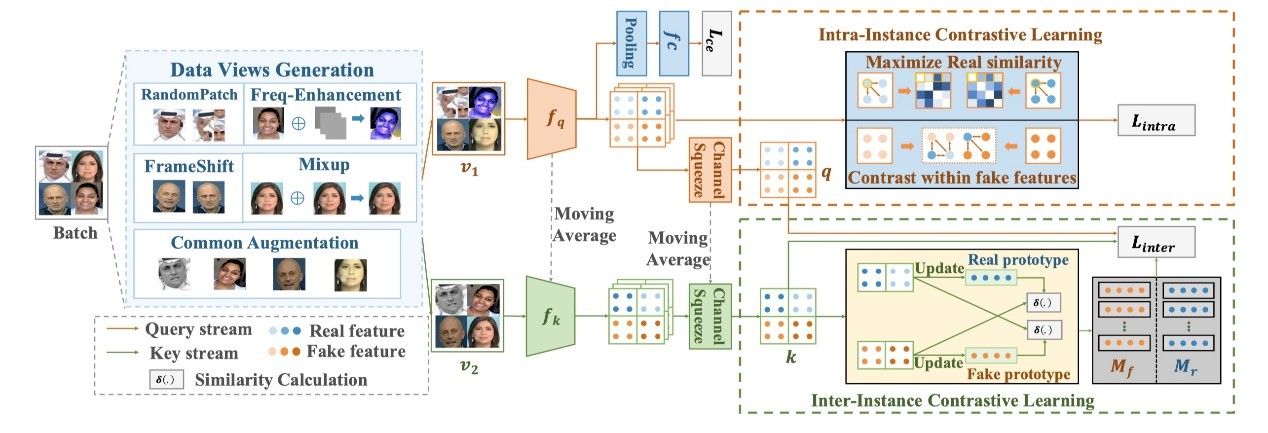
12.Dual Contrastive Learning for General Face Forgery Detection (发表于AAAI 2022)
本文的第一作者是我院人工智能系2021级博士生孙可,通讯作者是我院人工智能系纪荣嵘教授。本文提出了一个新型的人脸伪造检测框架,即双对比学习(Dual Contrastive Learning,DCL),其针对性地设计了真假配对数据,并在不同的粒度上进行对比学习得到更泛化的特征表示。具体而言,本文结合硬样本选择策略提出了实例间对比学习(Inter-ICL),通过针对性构建实例对来促进任务相关的判别性特征学习。此外,为了进一步探索本质上的差异,本文还引入了实例内对比学习(Intra-ICL),通过构建实例内的局部区域对来关注伪造人脸中普遍存在的局部内容不一致性。
本文在WildDeepfake以及DFDC等多个学术数据集下取得了良好表现,尤其在跨域场景下,本文方法取得了SOTA性能,可视化分析进一步呈现了本文所提出的双对比学习框架的有效性。
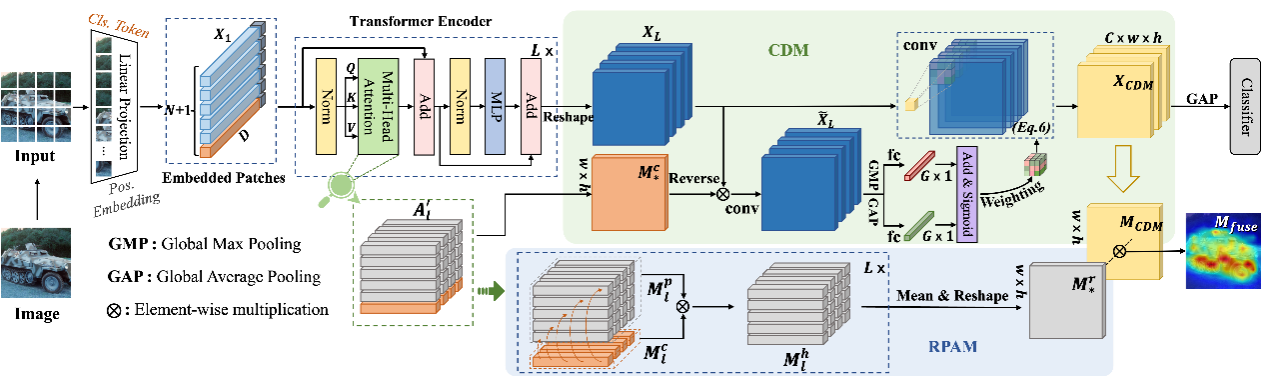
13.LCTR: On Awakening the Local Continuity of Transformer for Weakly Supervised Object Localization (发表于AAAI 2022)
本文的第一作者是我院人工智能系2020级博士生陈志威,通讯作者是我院计算机科学与技术系曹刘娟副教授。弱监督目标定位(WSOL)旨在实现仅给定图像级标签的前提下学习一个目标定位器。基于卷积神经网络的技术往往会过分突出目标最具判别力的区域从而导致忽略目标的整体轮廓。最近,基于自注意力机制和多层感知器结构的transformer因其可以捕获长距离特征依赖而在WSOL中崭露头角。美中不足的是,transformer类的方法缺少基于CNN的方法中固有的局部感知倾向,从而容易在WSOL中丢失局部特征细节。在本文中,我们提出了一个基于transformer的新颖框架,叫作LCTR(局部拓展性Transformer),从而在transformer中长距离全局特征的的基础上增强局部感知能力。具体地,本文提出了一个关联块注意力模块来引入图像块之间的局部关联关系。此外,本文还设计了一个细节挖掘模块,从而可以利用局部特征来引导模型学习者去关注那些弱响应区域。最后,本文在两大公开数据集CUB-200-2011和ILSVRC上进行了充分的实验来验证方法的有效性。
CVPR作为计算机视觉和模式识别领域的顶级会议,也被称为计算机视觉领域的“奥斯卡”。在快速更新迭代的计算机学科中,CVPR凭借其严苛的论文收录标准,已成为全球AI领域团队检验自身基础研究成果的试金石,每年都吸引大量研究机构及高校等参与其中。
IJCAI是人工智能领域顶级的学术会议之一,是中国计算机学会(CCF)推荐的A类国际学术会议。本次IJCAI一共收到4535篇投稿论文,最终录取比例为15%
AAAI是由国际人工智能促进协会主办的年会,是人工智能领域中历史最悠久、涵盖内容最广泛的国际顶级学术会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议。本次AAAI共收到全球的9215篇投稿论文,接受率为15%。